约束可以理解成 数据库提供的一种针对数据的合法性进行验证的机制, 在创建表的时候使用
1. 约束类型
- NOT NULL - 指示某列不能存储 NULL 值, 表里的这个内容是必填项
- UNIQUE - 保证某列的每行必须有唯一的值, 不能重复 每次插入/修改时, 都要先触发查询, 如果当前插入/修改的值已经存在, 就会插入/修改失败
- DEFAULT - 规定没有给列赋值时的默认值 一般在指定列插入时会用到, 如果没有规定默认值, 默认值就为NULL
- PRIMARY KEY - 主键 NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
- FOREIGN KEY - 外键 涉及到两个表之间的关系 保证一个表中的数据匹配另一个表中的值的参照完整性。
- CHECK - 保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略CHECK子句
2. not null
create table 表名 (列名 类型 not null,...);
创建一个学生表, 如果没加not null:

Null这一列为YES, 表示这一列可以为空
加上not null:
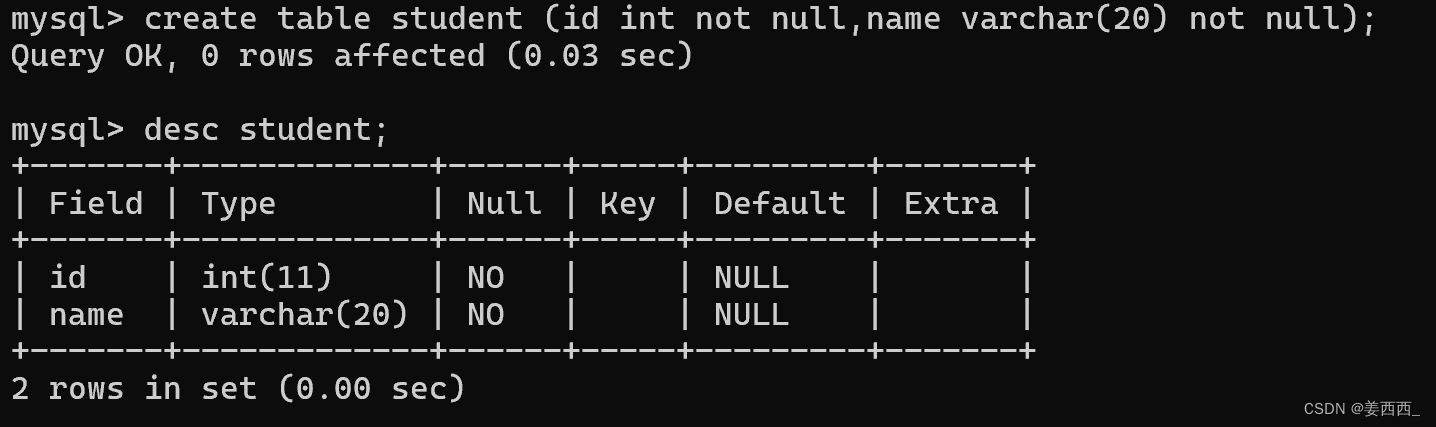
Null这一列为NO, 表示这一列不可以为空
当我们在对这一列的数据进行添加和修改时, 不可以附空值:

2. unique
create table 表名 (列名 类型 unique,...);
创建一个学生表, 如果没加unique:

是允许插入重复数据的
加上unique:
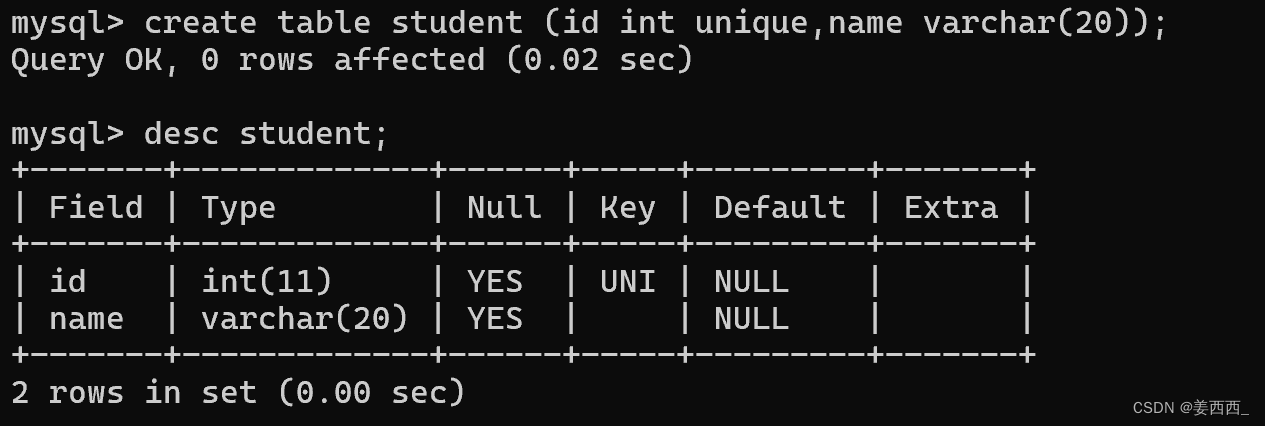
KEY这一列中id为UNI, 表示id这一属性是unique的
当我们在对这一列的数据进行添加和修改时, 不可以添加和修改为重复值:

3. default
create table 表名 (列名 类型 default 默认值,...);
创建一个学生表, 如果没加default:

没有指定id为2时的name, 那么默认值为NULL
加上default:

Default这一列对应的name为'无名氏', 将name的默认值设为'无名氏'
再进行指定列插入时, 不指定name:

4. primary key
create table 表名 (列名 类型 primary key,...);
注意: 一个表中只能有一个主键, 但一个主键不一定只对应一个列, 可以是多个列联合作为主键, 称为联合主键
指定student表中id作为主键:

Key这一列id为PRI, 表示id为主键, 并且Null为NO, 主键不能为NULL
因为主键的条件是not null + unique, 所以可以这样定义:
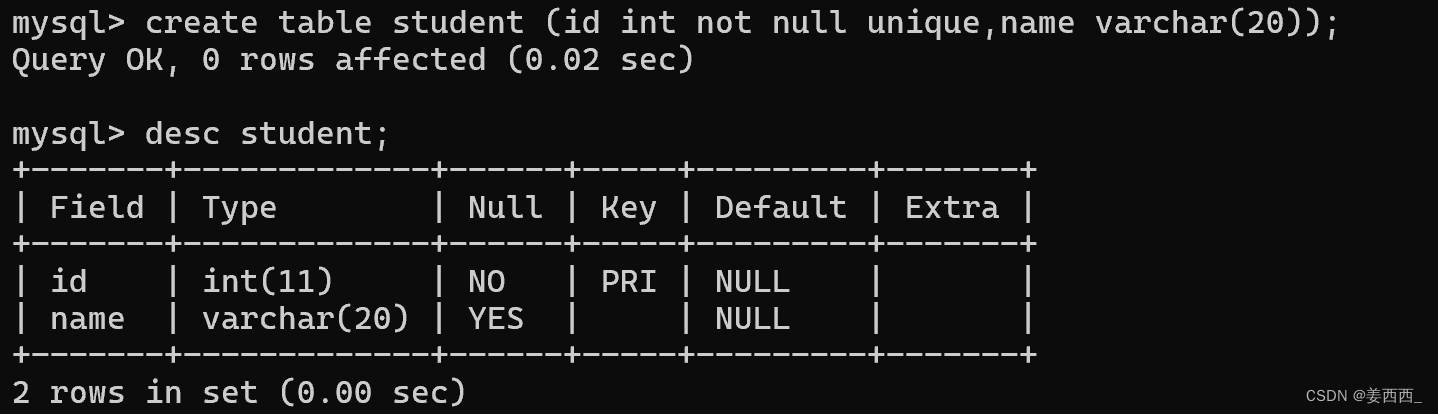
默认也是主键
自增主键:
一般来说, 我们会使用整数id作为主键, 那么在实际开发中, 我们如何保证id的值是非空且唯一的呢?
在mysql中提供了"自增主键", 在每次插入新的数据时, 都能把主键基于最大的主键值+1
语法:
create table 表名 (列名 类型 primary key auto_increment,...);
例:
将学生表的id设为自增主键
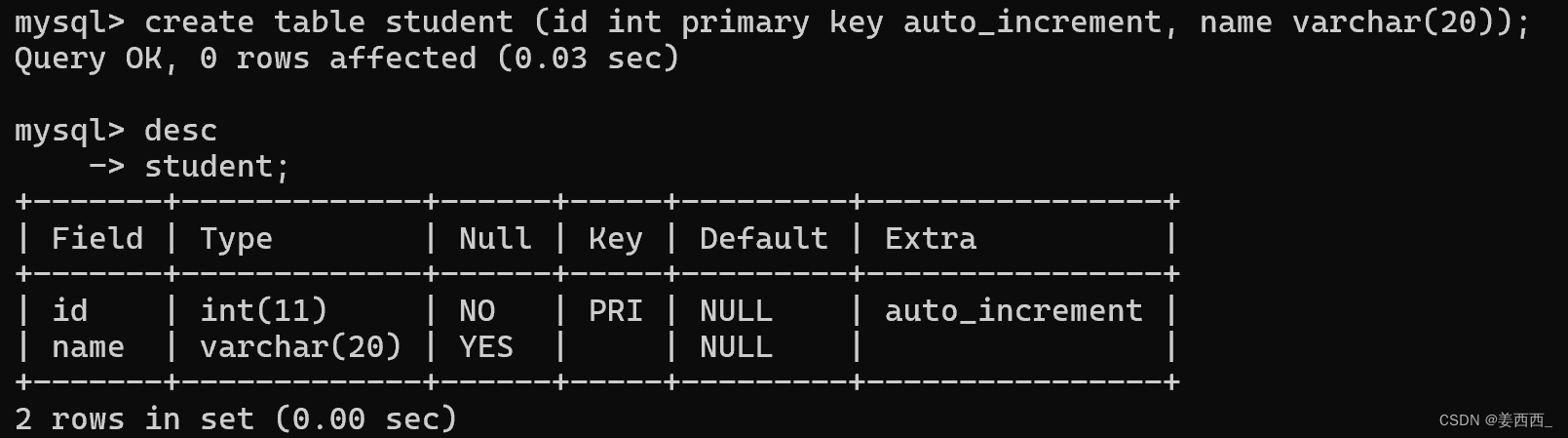
Extra中auto_increment就是对自增主键的说明
插入数据:

此时, 插入的null并非是真的null值, 而是根据自增规则, 自动插入数据, 默认从0开始自增

当然这种情况下, 我们也可以手动指定id, 不一定非要依赖自增主键:
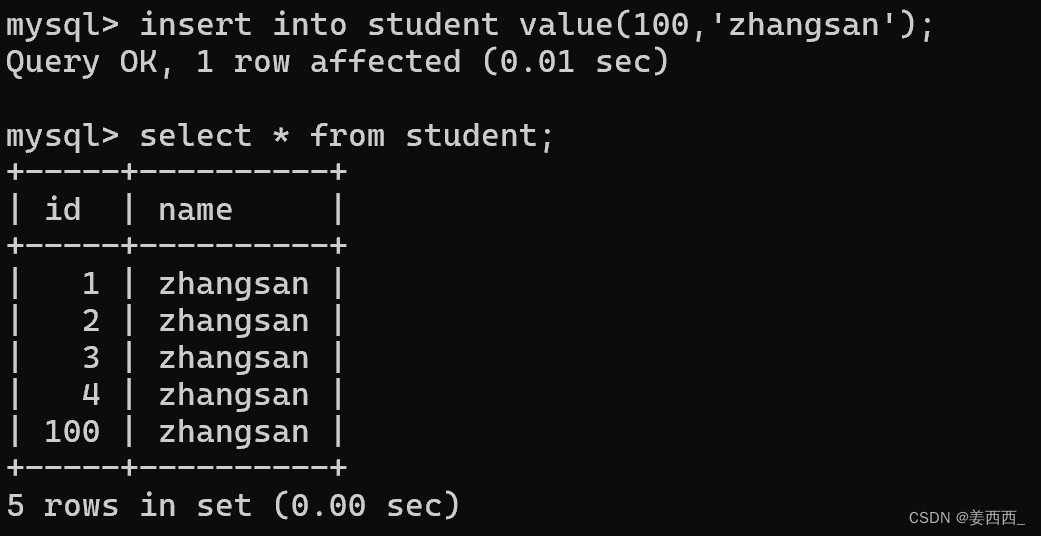
此时再次指定null, 下一个id应该是101:

如果将id为100和101都删去, 再次插入null, 下一个id是102!

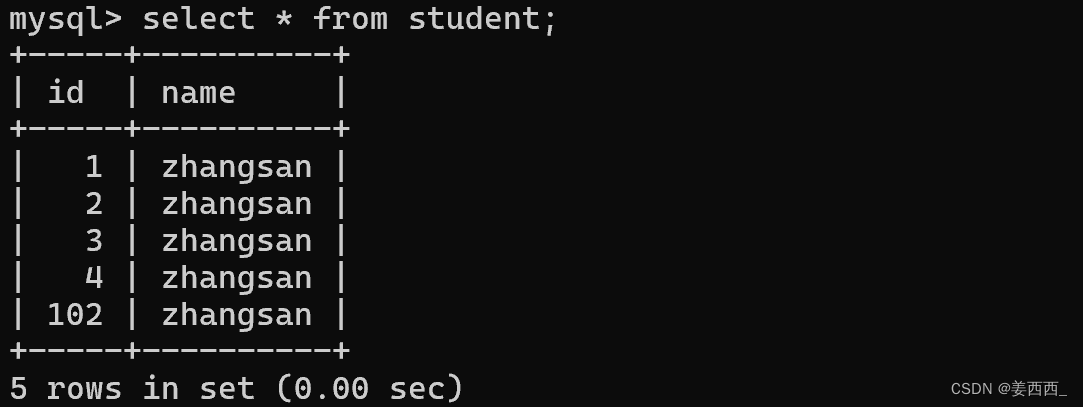
如此, 5-99这些id, 就不会再自增主键时出现了
基于分布式系统下生成唯一id:
自增主键, 本质上上mysql服务器存储了当前表中的最大id, 再进行累加的, 但是如果基于分布式系统, 存储数据的时候, 每一个机器都存储了部分数据, 这些数据分别都有最大值, 那么显然"自增主键"就无能为力了
那么在分布式系统中, 生成唯一id算法有很多种, 此处给出一个最简单最朴素的方式, 其他的生成算法核心思路大同小异的:
时间戳(ms) + 机器的编号(应用程序所谓机器) + 随机因子(随机数)
---> 得到一个字符串
---> 计算hash值, 得到一个整数, 作为id
简单介绍计算字符串hash值的算法:
java中自带一个比较简单的计算方式, 但是在实际开发中用得不多, 在实际开发中, md5, sha1用的多, 但其实这几种算法都是数学问题, 只是套用的公式不同, 想要了解具体的算法并不容易, 但我们更关注的是算法的特性
以md5 为例(其他大同小异), 主要有三个方面特性:
- 定长 无论输入的字符串多长, 最终算出来的hash值都是一样长的
- 分散 输入的字符串, 那怕只有一点点不一样, 得到的md5值都会差异很大 (这也是称为hash算法的根本)
- 不可逆 给你原始字符串, 计算hash值, 对计算机来说非常简单, 但黑泥hash值,还原成原始的字符串, 理论上不可行
5. foreign key
create table 表名 (列名 类型 , 列名 类型, ... , foreign key (当前表中(子表)的某一列名) references 表名2 (表名2中(父表)的某个列名));
注意: 引用父表的这个列, 要么是主键, 要么是unique, 不然不能当做外键使用
例:
如果不加外键链接, 创建student表和class表:


给class添加数据:

给student添加数据:

此时我们看到, 给学生班级id设成100也是可以通过的, 但实际班级id没有100, 所以就会出现问题
加外键链接, 创建student表和class表:


此时, student的classID和class的classID就建立了联系, student中classID的值, 必须在class中classID中存在!!
class表, 就对student表产生了制约, 此时就把class表(制约别人的表) 称为"父表"(parent table), 把student表(被制约的表) 称为"子表"(child table)
此时向表中添加数据:

因为class表中没有classID为100的班级, 所以添加失败, 触发了外键约束
删除父表中的外键约束:

删除classID为3可以成功, 而删除classID为1不成功, 因为在子表中已经使用个这个classID
所以实际上, 确实是父亲约束儿子, 儿子不能随意添加和修改, 但同时儿子也在约束父亲, 不能随意删除和修改, 是双向约束的过程!!
考虑一个场景: 一个电商网站, 肯定会有两个数据库:
商品表(id,name,price...)
订单表(orderid, ...,goodid)
订单表中, 存在一些记录, 引用自商品表的某个数据
未来某一天, 我不买这个商品了, 要下架, 如果这时想要删除这件商品, 还不被允许的, 那应该怎么办呢?
答案是: 添加标记字段
商品表(id,name,price... isOK)
isOK如果是1, 表示有效数据, isOK是0, 表示无效数据
当我们要删除商品时, 不再是delete, 而是将isOK改成0, 后续用户查询商品列表时, 也是通过条件, 只返回isOK为1的记录, 此时即保证了数据能够删除, 也不违背外键约束, 这种删除称为逻辑删除
其实在硬盘上删除一个文件, 也不是说把硬盘上的对应空间的数据给擦除, 也是标记成无效(标记成无效后, 可能就会被系统用来存储别的数据了)
那么如何删除数据才是安全的呢? --- 物理删除!!(把硬盘砸了)
6. check
check mysql5.7并不支持, 主要的作用是在执行语句之前判断是否满足check后的条件